Backend Engineering for High-Volume Data: Queues, Batching, and Backpressure
How backend systems stay reliable when requests, events, and data pipelines move faster than the application can process them.
Introduction: When Speed Becomes a Reliability Problem
Modern backend systems are rarely dealing with one piece of work at a time.
A user uploads a file. An API receives a request. A service emits an event. A logging pipeline collects telemetry. A document-processing system extracts text, chunks content, generates embeddings, and writes results into a database or search index.
Each individual operation may be simple. The hard part begins when thousands or millions of these operations arrive faster than the system can safely process them.
At low volume, backend engineering can feel straightforward:
Receive a request, do the work, return a response.
But at higher volume, this model starts to break down. The application may still be accepting requests, but workers fall behind. A database may become the bottleneck. Retries may create even more load. A queue may grow quietly in the background until “successful” requests are actually taking minutes or hours to complete.
This is where reliability becomes a flow-control problem.
A high-volume system needs a way to absorb bursts, process work efficiently, and protect itself when downstream services slow down. That is the role of queues, batching, and backpressure.
Queues separate accepting work from completing work.
Batching allows the system to process groups of work more efficiently than handling every item individually.
Backpressure gives the system a way to slow down, reject, pause, or reshape incoming work before overload spreads through the pipeline.
These ideas matter in traditional backend systems, but they are especially important in data-heavy and AI-heavy applications. A document ingestion pipeline, for example, may need to handle uploads, virus scanning, text extraction, chunking, embedding generation, metadata storage, and indexing. If any part of that chain slows down, the system needs to degrade safely instead of collapsing.
This post walks through how queues, batching, and backpressure work together to keep high-volume backend systems reliable when requests, events, and data pipelines start moving faster than the application can process them.
The Core Problem: Producers Can Outrun Consumers
Most high-volume backend problems can be reduced to a simple model:
Producers create work, and consumers process work.
A producer might be an API receiving user requests, a service publishing events, a logging agent sending telemetry, or an upload system creating document-processing jobs.
A consumer might be a background worker, stream processor, database writer, embedding service, or indexing service.
At small scale, the difference between the two is easy to ignore. If one request arrives and one worker can process it quickly, the system feels simple.
But high-volume systems are not defined by one request. They are defined by rates.
If an upload API accepts 1,000 files per minute, but the document-processing workers can only process 400 files per minute, the system is not stable. Even if every individual worker is functioning correctly, the backlog grows by 600 files every minute.
That gap is where reliability problems begin.
The application may still return successful responses. The API may still be online. The database may still be accepting writes. But internally, the system is falling behind. Jobs wait longer. Queues grow deeper. Retries become more expensive. Temporary delays can turn into permanent operational pressure.
This is why high-volume backend engineering is not only about making individual operations faster. It is also about understanding flow.
A system has to answer questions like:
- How quickly is work arriving?
- How quickly can we process it?
- What happens when processing slows down?
- Where does work wait?
- How much waiting is acceptable?
- When should the system stop accepting more work?
For example, consider a document-processing pipeline in an AI application. A user uploads a file, then the system scans it, extracts text, splits it into chunks, generates embeddings, and indexes those embeddings for retrieval. Each step may depend on a different service or database.
If embedding generation slows down because of an external API rate limit, the upload API may still continue accepting files. That creates a dangerous illusion: the system looks healthy at the entry point, but work is accumulating deeper in the pipeline.
The same pattern appears in many backend systems:
| System | Producer | Consumer | Backlog symptom |
|---|---|---|---|
| Order processing | Checkout service | Fulfilment workers | Delayed orders |
| Logging pipeline | Application servers | Log processors | Consumer lag |
| File uploads | Upload API | Processing workers | Pending files |
| Notification system | Event service | Email/SMS workers | Late messages |
| AI ingestion pipeline | Document service | Embedding/indexing workers | Stale search results |
The core problem is not just traffic volume. It is the mismatch between input rate and processing capacity.
Once that mismatch exists, the system needs tools to manage it. Queues help absorb bursts. Batching helps consumers process work more efficiently. Backpressure helps the system slow down before overload spreads.
Without those controls, a high-volume system can keep saying “yes” to new work long after it has lost the ability to finish the work it already accepted.
Queues: Decoupling Work from Processing
A queue is one of the simplest ways to make a backend system more resilient under load.
Instead of forcing the application to complete every task during the original request, the system can place work onto a queue and process it asynchronously. In this context, asynchronous means the work does not have to finish immediately before the user gets a response.
sequenceDiagram
participant User
participant API as API Service
participant Queue
participant Worker
participant DB as Database/Search Index
User->>API: Submit request or upload file
API->>Queue: Publish background job
API-->>User: Return accepted response
Queue->>Worker: Deliver job when worker is ready
Worker->>DB: Process and store result
Worker-->>Queue: Acknowledge completionFor example, imagine a user uploads a document to an AI application. The system may need to scan the file, extract text, split the text into chunks, generate embeddings, store metadata, and update a search index.
Doing all of that inside the original upload request would be fragile. The user would be waiting while multiple downstream systems run. If the embedding service slows down, the upload endpoint slows down. If the search index is temporarily unavailable, the whole request may fail.
A queue changes that flow.
The upload service can accept the file, store it safely, publish a processing job to a queue, and return a response such as:
Document uploaded. Processing has started.The heavier work then happens in the background.
A minimal API handler might look like this:
from fastapi import FastAPI, UploadFile, status
app = FastAPI()
@app.post("/documents", status_code=status.HTTP_202_ACCEPTED)
async def upload_document(file: UploadFile):
document_id = await storage.save(file)
await queue.publish({
"job_type": "process_document",
"document_id": document_id,
})
return {
"document_id": document_id,
"status": "accepted",
}The API does not process the whole document in the request path. It accepts responsibility for the work, publishes a job, and returns quickly.
This separation matters because high-volume systems often have uneven workloads. The part of the system that accepts work may be able to move much faster than the part that processes work. A public API might accept thousands of requests per minute, while the workers responsible for processing those requests may depend on slower databases, external services, or expensive compute.
A queue gives the system breathing room.
It allows the API layer to stay responsive while workers process jobs at a controlled pace. It also allows the system to handle short traffic spikes without immediately failing every request. If 10,000 events arrive in one minute, they do not all need to be processed in that same minute, as long as the backlog remains within acceptable limits.
Queues are commonly used for tasks like:
- Sending emails or notifications.
- Processing uploaded files.
- Generating image thumbnails.
- Writing analytics events.
- Running payment or fulfilment workflows.
- Consuming logs and telemetry.
- Generating embeddings for retrieval systems.
- Updating search indexes.
The important point is that a queue does not make the work disappear. It only moves the work out of the immediate request path.
That is powerful, but it also requires discipline. Once work is placed on a queue, the system needs workers to process it, retry logic for temporary failures, visibility into queue depth, and a clear policy for what happens when jobs fail permanently.
A queue is not just a storage layer for tasks. It is a boundary between two parts of the system:
accepting work → processing workThat boundary gives backend engineers more control. They can scale workers separately from the API. They can pause processing when a downstream dependency is unhealthy. They can retry failed jobs without asking the user to resubmit the request. They can also prioritise certain types of work over others.
In high-volume systems, this separation is often the difference between a user-facing outage and a manageable backlog.
But queues come with a trap: because the API can continue accepting work, the system may look healthy even when the queue is growing dangerously behind the scenes.
That is the hidden danger we need to look at next.
The Hidden Danger of Queues: They Can Hide Failure
Queues are useful because they let a system absorb work without processing everything immediately. But that same property creates one of their biggest risks.
A queue can make a system look healthier than it really is.
Imagine an upload API that accepts documents and places each processing job onto a queue.
From the user’s perspective, the upload succeeds. From the API’s perspective, the request was handled quickly. The service might return:
202 AcceptedThat response means the system has accepted the work. It does not mean the work has been completed.
This distinction matters.
If the workers are processing jobs fast enough, the queue remains stable. Jobs enter, jobs leave, and the system stays balanced. But if workers slow down, or if a downstream dependency becomes unreliable, the queue starts to grow.
At first, nothing may look obviously broken. The API is still online. Requests are still being accepted. Logs may show successful responses. Dashboards for the web service may look normal.
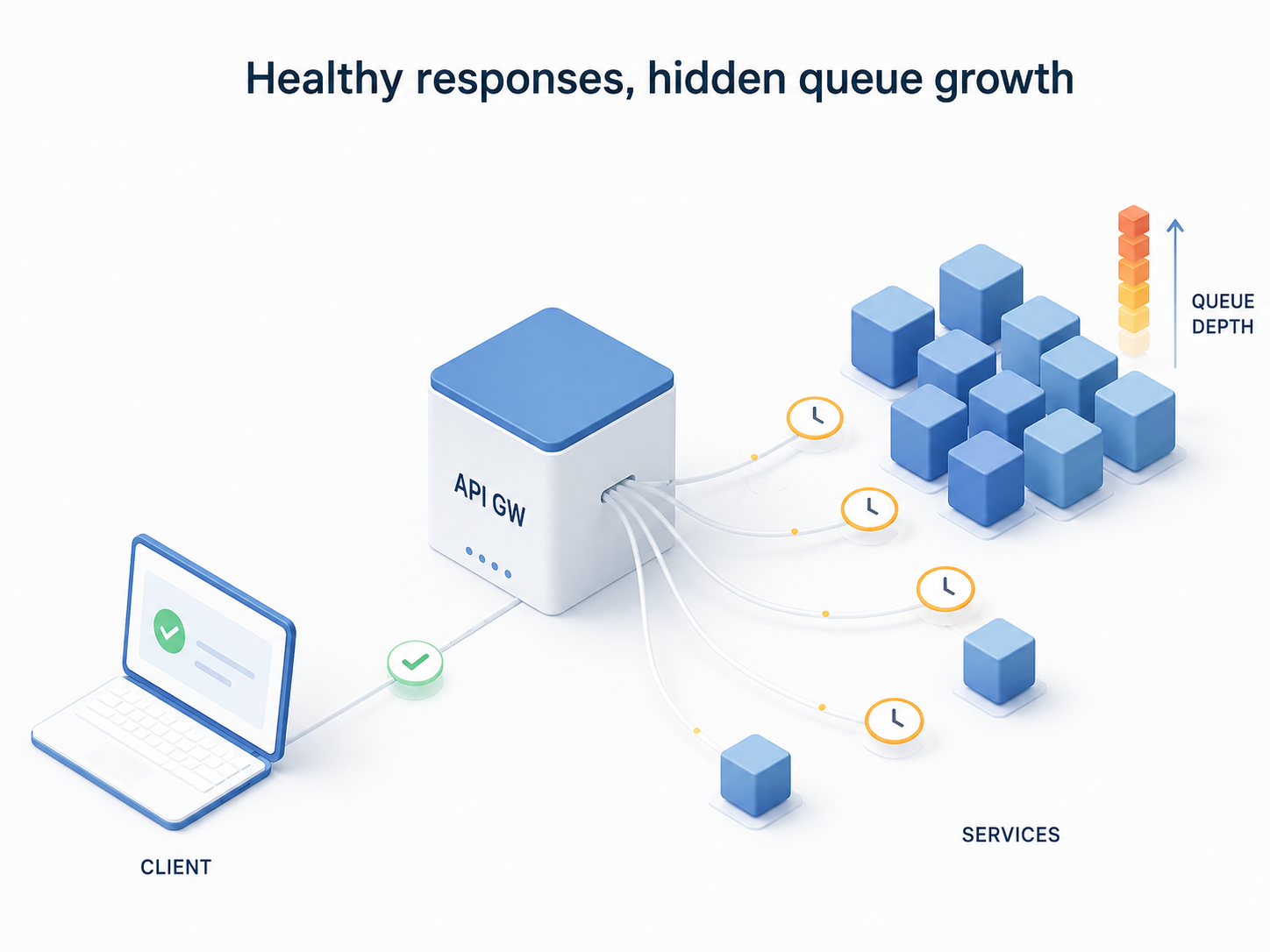
But internally, the system is falling behind.
A growing queue is usually a sign that the system is accepting work faster than it can complete it. This may be fine for a short burst. For example, a temporary spike in uploads may create a backlog that workers clear a few minutes later.
But if queue depth keeps increasing over time, the queue is no longer smoothing traffic. It is hiding overload.
That is the difference between a healthy queue and a dangerous one.
A healthy queue absorbs short-term unevenness.
An unhealthy queue becomes a waiting room for work the system has no realistic capacity to finish on time.
This can create several failure modes.
First, jobs become stale. A notification sent one minute late may be acceptable. A password reset email sent two hours late is not. A document indexed after a few seconds may feel normal. A document indexed the next morning may look like a broken product.
Second, retries can make the problem worse. If a downstream service fails, workers may retry the same jobs again and again. Without limits or delays, retries add more load to an already stressed system. This is known as a retry storm, where recovery attempts create even more pressure.
Third, the queue itself can become a resource problem. Depending on the system, a large backlog may consume memory, disk, broker storage, or database capacity. The queue was introduced to protect the application, but it can become another overloaded component.
Finally, users may lose trust because the system’s external behaviour becomes misleading. The application says the request succeeded, but the result does not appear. From the user’s point of view, that feels like failure, even if the backend technically “accepted” the job.
This is why queues need operational boundaries.
A production queue-based system should usually have answers to questions like:
- How deep can the queue grow before we consider it unhealthy?
- How old can the oldest job be?
- How many times should a job be retried?
- What happens after the final retry fails?
- Should lower-priority jobs be dropped, delayed, or moved elsewhere?
- When should the API stop accepting more work?
The key lesson is that a queue does not remove failure. It changes the shape of failure.
Without monitoring and limits, a queue can turn an immediate error into a delayed, harder-to-debug problem. The system may keep accepting work long after it has lost the ability to process that work within an acceptable time.
That is why queues usually need to be paired with two other ideas: batching, to improve processing efficiency, and backpressure, to stop overload from spreading.
Batching: Processing More Work with Less Overhead
Once work is sitting in a queue, the next question is how the system should process it.
The simplest option is to process one item at a time. A worker takes one job from the queue, processes it, writes the result, acknowledges the job, then moves to the next one.
That model is easy to reason about, but it can be inefficient at high volume.
Many backend operations have fixed overhead. Opening a network connection, making an API call, writing to a database, committing a transaction, or sending data across the network all carry some cost. If the system pays that cost for every single item, throughput can suffer.
Batching improves this by grouping multiple items together and processing them as a unit.
Instead of writing one database row at a time, a worker may write 500 rows in a single bulk insert. Instead of sending one log event per request, a logging agent may buffer events and send them every few seconds. Instead of generating one embedding at a time, an AI pipeline may group multiple chunks into a single embedding request.
The goal is not just to make the code faster. The goal is to reduce repeated overhead.
For example, imagine a document-ingestion system that has already split uploaded documents into chunks. Each chunk needs to be converted into an embedding before it can be stored in a vector database. Sending one request per chunk may work during testing, but under real load it can become slow, expensive, and rate-limit prone.
A batching layer can group chunks together:
100 chunks → one embedding requestThat allows the system to process more items with fewer calls.
The same idea appears across backend systems:
| Use case | Without batching | With batching |
|---|---|---|
| Database writes | Insert one row per request | Bulk insert many rows |
| Logging | Send one log event at a time | Flush logs every few seconds |
| Queue processing | Handle one message per worker loop | Pull and process messages in batches |
| Embeddings | One API call per text chunk | One request containing many chunks |
| Analytics | Write every event immediately | Buffer and write events together |
Batching is especially useful when the bottleneck is not the actual computation, but the overhead around it.
However, batching is not free.
The main trade-off is throughput versus latency.
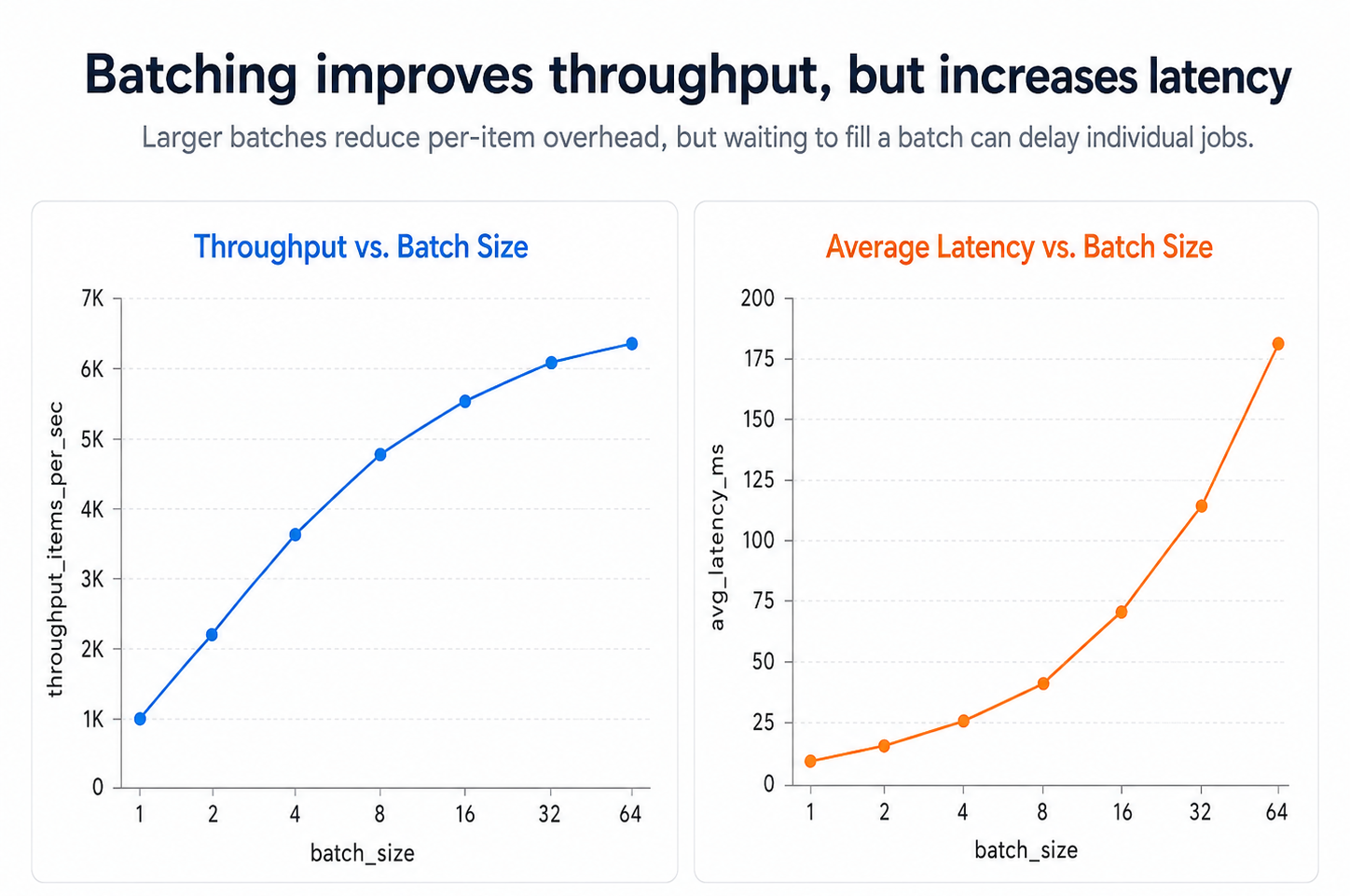
A larger batch can improve throughput because the system does more useful work per operation. But a larger batch can also increase latency because individual items may wait longer before the batch is full.
For example, if a worker waits until it has 1,000 events before writing to the database, the database may be used efficiently. But if traffic slows down, the first event in that batch may sit around waiting for the other 999 events to arrive.
That is why production batching usually needs two limits:
Process the batch when it reaches N items
or
Process the batch after T secondsThis prevents low-volume periods from creating unnecessary delay.
A simple batching loop might look like this:
import asyncio
import time
async def collect_batch(queue, max_size: int, max_wait_seconds: float):
batch = []
deadline = time.monotonic() + max_wait_seconds
while len(batch) < max_size:
timeout = max(0, deadline - time.monotonic())
try:
item = await asyncio.wait_for(queue.get(), timeout=timeout)
batch.append(item)
except asyncio.TimeoutError:
break
return batchThis structure avoids waiting forever for a perfect batch size. The worker processes the batch when either the item limit or the time limit is reached.
Batching also changes failure handling. If a batch of 100 items fails, the system needs to decide what failed. Did every item fail, or only one invalid item inside the batch? Should the whole batch be retried? Should the batch be split into smaller groups? Should one bad item be moved to a dead-letter queue?
These details matter because a poorly designed batching system can amplify problems. One malformed record should not permanently block 999 valid records behind it.
A practical batching design usually considers:
- Maximum batch size.
- Maximum wait time.
- Downstream rate limits.
- Maximum payload size.
- Retry behaviour.
- Partial failure handling.
- Memory usage while buffering.
- Whether the operation is idempotent.
Idempotent means the same operation can be safely repeated without creating duplicate or incorrect results. This matters because batch jobs often need retries. If a worker writes a batch to a database and then crashes before acknowledging the queue message, the same batch may be processed again. The system should be designed so that retrying does not corrupt the result.
Batching is one of the most useful tools in high-volume backend systems because it lets consumers drain work more efficiently. But it has to be tuned carefully.
Small batches may waste capacity. Large batches may increase latency. Unbounded batches may create memory pressure. Poor retry handling may turn one bad item into a much larger processing failure.
The best batching systems are not simply the ones with the largest batch size. They are the ones that find a safe operating point between efficiency, latency, and reliability.
Backpressure: Teaching the System to Say “Slow Down”
Queues help absorb bursts. Batching helps process work more efficiently. But neither solves the problem of unlimited demand.
At some point, a system has to say:
We cannot safely accept more work at this speed.
That is backpressure.
Backpressure is a way for a system to signal that downstream capacity is limited. Instead of letting requests, events, or jobs pile up forever, the system slows producers down, rejects some work, pauses processing, or reduces the rate at which work moves through the pipeline.
A simple example is an API rate limit. If a client sends too many requests too quickly, the API may respond with:
429 Too Many RequestsThat response is not just an error. It is a control signal. The system is telling the client to slow down before the service becomes unstable.
Backpressure can appear in different parts of a backend system:
| Backpressure mechanism | What it does | When it helps |
|---|---|---|
| Rate limiting | Slows incoming requests | Public APIs or noisy clients |
| Queue size limit | Prevents unlimited backlog | Background job systems |
| Consumer pause | Stops pulling more messages | Downstream service is unhealthy |
| Retry backoff | Waits before retrying failed work | Temporary failures |
| Load shedding | Drops lower-priority work | System is near overload |
| Worker concurrency limit | Caps active jobs | Protects databases or APIs |
The important idea is that backpressure makes overload visible and controlled.
Without it, a system may keep accepting work until the queue becomes enormous, workers run out of memory, retries multiply, and downstream services collapse. With backpressure, the system can degrade more safely.
For example, in a document-processing pipeline, the embedding service may have a strict rate limit. If workers ignore that limit, they will keep sending requests, receive failures, retry aggressively, and make the backlog worse.
A better design would slow the embedding workers down, reduce concurrency, retry with backoff, and let the queue absorb only a controlled amount of waiting work.
A simple API-side queue limit might look like this:
from fastapi import HTTPException, status
MAX_QUEUE_DEPTH = 50_000
async def publish_processing_job(job: dict):
depth = await queue.depth("document-processing")
if depth >= MAX_QUEUE_DEPTH:
raise HTTPException(
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
detail="Processing capacity is temporarily limited. Please retry later.",
)
await queue.publish(job)This is not the only way to apply backpressure, but it shows the principle: the system should not blindly accept infinite work when it already knows processing is falling behind.
Backpressure is not always pleasant. Sometimes it means users wait. Sometimes it means requests are rejected. Sometimes it means low-priority jobs are delayed.
But that is better than pretending the system is healthy while it quietly falls behind.
In high-volume backend systems, reliability often depends on knowing when to process faster and when to slow the system down deliberately.
Putting It Together: A High-Volume Data Pipeline Example
Consider a document-processing system for an AI application.
A user uploads a file, and the system needs to make that file searchable. Behind the scenes, this may involve several steps:
- Store the original file.
- Scan it for viruses.
- Extract the text.
- Split the text into chunks.
- Generate embeddings.
- Store metadata.
- Index the content for retrieval.
A fragile design would try to do all of this inside the upload request.
That might work in a demo, but it breaks down quickly in production. If text extraction is slow, the upload request becomes slow. If the embedding provider hits a rate limit, the whole request may fail. If the vector database is unavailable, the user may need to upload the same document again.
A better design separates the pipeline into stages.
flowchart LR
A[User Uploads Document] --> B[Upload API]
B --> C[Object Storage]
B --> D[Processing Queue]
D --> E[Virus Scan Worker]
E --> F[Text Extraction Worker]
F --> G[Chunking Worker]
G --> H[Embedding Batcher]
H --> I[Vector Database]
G --> J[Metadata Database]
H -. rate limit / backpressure .-> D
D -. queue depth limit .-> B
E -. failed jobs .-> K[Dead Letter Queue]
F -. failed jobs .-> K
H -. failed jobs .-> KThe upload API should do the minimum safe work: accept the file, store it, create a processing job, and return a response. The heavier work can happen asynchronously through queues and workers.
Each stage can then be managed separately.
The virus scan worker does not need to run at the same speed as the upload API. The text extraction worker may need more CPU. The embedding stage may need batching because calling an embedding model one chunk at a time is inefficient. The indexing stage may need retry logic if the search database is temporarily slow.
This is where the three ideas come together.
Queues separate the stages so that one slow part does not block the whole request path.
Batching helps expensive stages process more efficiently, especially embedding generation or database writes.
Backpressure prevents the pipeline from accepting unlimited work when a downstream stage cannot keep up.
For example, if the embedding service has a rate limit, the system should not allow workers to keep pulling jobs endlessly. It may reduce worker concurrency, slow down batch submission, or let the queue grow only up to a safe limit. If the backlog becomes too large, the upload API may need to reject new work temporarily or tell users that processing is delayed.
This is the difference between a pipeline that merely works and a pipeline that behaves predictably under pressure.
The goal is not to make every stage infinitely fast. The goal is to make the flow of work visible, controlled, and recoverable.
A reliable high-volume backend should know:
- Where work is waiting.
- Which stage is the bottleneck.
- How long jobs are taking.
- When to retry.
- When to slow down.
- When to stop accepting more work.
That is what turns a chain of background jobs into an engineered system.
What to Monitor in Production
A queue-based system is only reliable if you can see what is happening inside it.
The API might look healthy while background workers are falling behind. That is why production monitoring needs to include the pipeline, not just the user-facing service.
The most useful metrics are usually the ones that show whether work is flowing through the system at a safe rate.
| Metric | What it tells you | Bad sign |
|---|---|---|
| Queue depth | How much work is waiting | Keeps rising over time |
| Oldest job age | How long the oldest item has waited | Jobs are becoming stale |
| Consumer lag | How far workers are behind producers | Lag grows continuously |
| Processing latency | Time from accepted to completed | Users wait longer for results |
| Throughput | How much work is completed per second/minute | Drops while input stays high |
| Retry rate | How often jobs fail and retry | Sudden spike or retry loop |
| Dead-letter queue count | Jobs that failed permanently | Count keeps increasing |
| Downstream error rate | Health of databases, APIs, or services | Errors create backlog |
The key is not to watch these metrics in isolation.
A queue depth of 10,000 may be fine if workers normally clear that backlog in a few minutes. A queue depth of 500 may be dangerous if the oldest job has been waiting for two hours.
For high-volume systems, the most important question is:
Is the system recovering, or is it falling further behind?
Good monitoring should make bottlenecks visible. If the queue is growing, the system should show whether the problem is slow workers, a database bottleneck, an external API rate limit, bad retries, or a sudden spike in incoming work.
In a document-processing pipeline, for example, you would want to know:
- How many files are waiting to be scanned.
- How many are waiting for text extraction.
- How many chunks are waiting for embeddings.
- How long indexing takes.
- How many jobs failed permanently.
This gives engineers a clear view of where pressure is building.
A basic metric snapshot might include fields like this:
{
"pipeline": "document-processing",
"queue_depth": 12840,
"oldest_job_age_seconds": 420,
"jobs_completed_per_minute": 850,
"jobs_received_per_minute": 1100,
"retry_rate": 0.08,
"dead_letter_count": 14,
"embedding_api_error_rate": 0.03
}Monitoring is not just for dashboards. It should also drive alerts and operational decisions. If queue depth crosses a safe threshold, the system may need to scale workers, reduce concurrency, slow producers, or temporarily reject new work.
In high-volume data systems, visibility is part of the design. If you cannot see the backlog, delay, and failure rate, you cannot tell whether the system is reliable or just quietly falling behind.
Common Design Mistakes
Queues, batching, and backpressure are useful, but they can also be misused. A system can have all three and still fail if the design ignores production behaviour.
One common mistake is adding a queue and assuming the system is now reliable.
A queue only gives the system somewhere to hold work. If workers cannot drain the queue fast enough, the backlog still grows. Without metrics like queue depth, oldest job age, and retry rate, the failure just becomes harder to see.
Another mistake is retrying too aggressively.
Retries are useful for temporary failures, but they can make an outage worse if every failed job immediately tries again.
For example, this pattern is dangerous:
while True:
process(job)A safer approach uses limits and backoff:
import time
def retry_with_backoff(job, max_attempts: int = 5):
for attempt in range(max_attempts):
try:
process(job)
return
except TemporaryError:
delay = min(2 ** attempt, 30)
time.sleep(delay)
send_to_dead_letter_queue(job)This gives the system time to recover instead of repeatedly hitting the same failing dependency.
Batching can also cause problems when it is too aggressive. Very large batches may improve throughput, but they can increase latency, memory usage, and failure impact. If one bad record causes a whole batch to fail, the system needs a way to isolate that record rather than blocking everything behind it.
Another common issue is treating 202 Accepted as if it means the work is complete.
It does not. It only means the system accepted responsibility for the work. If processing happens in the background, the product should make that state clear to users.
A final mistake is ignoring idempotency.
In distributed systems, the same job may be processed more than once because of retries, worker crashes, or acknowledgement failures. If repeating a job creates duplicate rows, duplicate emails, or duplicated payments, the system is fragile.
High-volume systems need to assume that delays, retries, partial failures, and duplicate processing will happen.
The goal is not to avoid every failure. The goal is to design the system so those failures are contained.
Closing Thoughts: Reliability Is Flow Control
High-volume backend systems do not stay reliable by accident.
As traffic grows, the main challenge is not just writing faster functions or adding more servers. The deeper challenge is controlling how work moves through the system.
Queues help by separating the moment work is accepted from the moment it is completed.
Batching helps the system process more work with less repeated overhead.
Backpressure helps the system slow down before overload spreads into every dependency.
Together, these patterns turn an overloaded system from something chaotic into something observable and manageable.
The goal is not to process unlimited work instantly. That is rarely realistic. The goal is to make the system behave predictably when demand exceeds capacity.
A reliable backend should know when to accept work, when to delay it, when to retry it, when to batch it, and when to reject it.
For engineers building data-heavy or AI-heavy systems, this matters even more. Pipelines for logs, documents, embeddings, analytics, search indexing, or model workflows often involve many stages moving at different speeds. Without flow control, one slow stage can quietly turn into a system-wide reliability problem.
The practical takeaways are simple:
- Use queues to decouple work from request handling.
- Monitor queue depth, lag, job age, retries, and failure rates.
- Batch expensive operations, but keep latency and failure handling in mind.
- Apply backpressure before queues grow without limit.
- Design jobs to be safely retried.
- Treat accepted as different from completed.
Queues, batching, and backpressure are not just infrastructure details. They are core backend engineering tools for keeping systems stable when data starts moving faster than the application can process it.